Understanding data mining: Recognizing patterns and seizing opportunities


Contents
Data mining: The key to hidden patterns in your data
Unimaginable amounts of data are generated every day, from online purchases and social media posts to sensor data in machines. But only a fraction of this information is actually used. The big question is: how do you turn raw data into valuable insights? This is exactly where data mining comes in: It brings order to the data chaos and makes patterns visible that move your company forward.
In this article, you will find out exactly what data mining is, which methods and techniques it uses, which practical use cases there are and which tools can support you. We also shed light on typical challenges, best practices for successful projects and the most important trends that will shape the use of data mining in the coming years.
What is data mining?
[DEFINITION][Data Mining][Data Mining is a systematic process for analyzing large data sets with the aim of discovering hidden patterns, trends and correlations and transforming them into useful information. This process is often referred to as Knowledge Discovery in Data (KDD) and forms the basis for data-driven decision-making in companies].
The main aim of data mining is to extract patterns, correlations and forecasts from extensive data sets that would remain hidden without computer-aided analysis. By using algorithms from artificial intelligence, machine learning and statistics, companies can gain insights that significantly influence their business strategies.
For better classification, it is important to distinguish data mining from related disciplines:
- Business intelligence focuses on preparing historical data and visualizing it in dashboards. It answers the question "What happened?".
- Machine learning on the other hand, uses algorithms to learn from data and make predictions.
- As an overarching discipline, data science encompasses all of these areas and more.
Data mining positions itself as the process that stands between pure data collection and practical application. It makes the hidden connections in your data visible and usable.
Methods and techniques in data mining
Data mining comprises various core tasks that are used depending on the issue at hand and the available data. Each method has its own specific strengths and is suitable for different application scenarios. The following methods are frequently used:
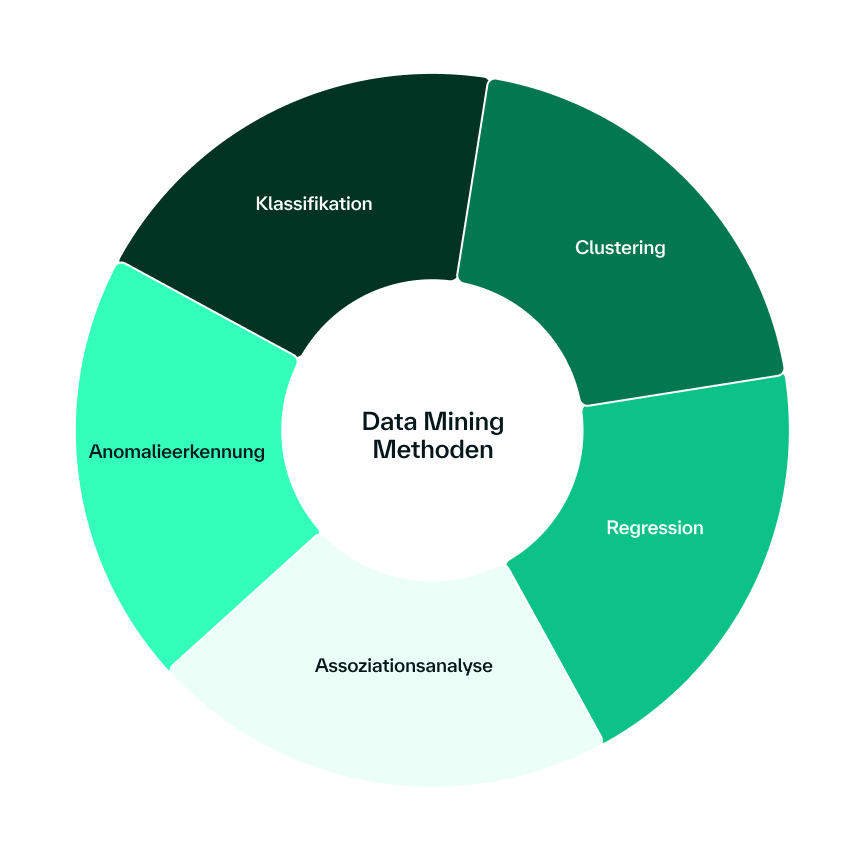
- Classification is a supervised learning method in which data points are assigned to predefined categories or classes. A model is trained on labeled data sets to recognize patterns and correctly classify new data. Typical applications can be found in spam detection, where emails are automatically classified as "spam" or "not spam", or in credit scoring, where customers are categorized into risk groups.
- Clustering works unsupervised and groups data points according to similarity without predefined classes. This method helps to discover unknown patterns and groupings in the data. A practical example is customer segmentation, where you divide your customers into different groups based on their purchasing behavior. Anomaly detection also uses clustering methods to identify unusual data points.
- Regression enables the prediction of continuous numerical values based on existing data and recognized correlations between variables. This data mining technique is used for price or sales forecasts, where you predict future sales figures based on historical data and external factors, for example.
- Association analysis identifies interesting relationships and patterns between different variables in large data sets. The best-known example is shopping basket analysis in retail, where it is possible to identify which products are frequently bought together. These findings enable targeted cross-selling strategies and optimized product placements.
- Anomaly detection detects conspicuous outliers or unusual patterns that deviate from the norm. This technique is particularly valuable for fraud detection. Unusual transaction patterns can indicate fraudulent activity, while anomalous network traffic patterns can signal cyberattacks.
The choice of the right method depends on several factors. experts emphasize that the type of data available determines the approach: For labeled data with known sample results, supervised learning methods such as classification or regression are suitable. Without labels, unsupervised methods such as clustering are used. The desired output type is also decisive: continuous values require regression, while discrete categories require classification methods. Data quality, available labels and the specific question ultimately determine which approach leads to success.
Practical use cases of data mining
Data mining reveals its true value in practical applications, where it solves specific business problems and creates measurable added value. The range of applications is impressive and continues to grow.
Fraud detection and security are among the most important fields of application. Payment providers such as Visa, Mastercard and PayPal use data mining to detect fraudulent transactions in real time. These companies have collected extensive data on normal payment transactions. If a payment transaction deviates significantly from these established patterns, an anomaly is detected and the transaction is flagged for further investigation. Similar approaches are used in cybersecurity, where unusual network activity indicates potential attacks.
Marketing and customer loyalty benefit considerably from data mining techniques. By segmenting your customers into different groups, you can develop tailor-made marketing strategies. This allows the budget to be distributed in a targeted manner: Customers with a high purchase probability, for example, receive a larger share of resources, while other groups are addressed with customized measures. This approach increases the efficiency of the campaigns and maximizes the return on investment.
Clustering algorithms offer practical solutions for complex customer segmentation that would not be manageable with conventional tools such as Excel. By systematically analyzing large customer databases, different customer types can be identified for which specific marketing and customer care approaches can be developed. This segmentation enables a much more efficient allocation of resources and a targeted customer approach.
Data mining is used in education to improve learning outcomes and enable personalized teaching. Educational institutions can use performance data to identify students at risk and provide them with support at an early stage. In addition, data mining-supported recommendation systems enable personalized course recommendations based on individual learning patterns and preferences.
Tools and instruments in data mining
Choosing the right tools can make the difference between the success and failure of your data mining project. Various solutions are available depending on the requirements, team skills and project goals.
Open source solutions offer a cost-effective entry into the world of data mining:
- Weka is particularly popular in research and teaching and offers a user-friendly interface with a variety of machine learning algorithms.
- Rapid Miner makes it possible to visually create and automate complete data mining workflows, from data pre-processing to model training.
- Orange scores with its focused visual interface and allows pipelines to be put together easily using drag-and-drop.
- KNIME is based on a modular node system and is often used in professional environments for workflow-supported analyses.
Programming languagesand frameworks offer maximum flexibility for complex requirements. Python has established itself as the standard language for data mining, supported by powerful libraries such as scikit-learn for machine learning, Pandas for data manipulation, NumPy for numerical calculations and Matplotlib and Seaborn for visualizations. TensorFlow and PyTorch are used for neural networks.
The choice between visual tools and programming language-based solutions depends on your team. practitioners recommend basing the choice on existing skills: Teams without programming experience benefit from visual workflow tools with pre-built modules that can be quickly assembled. However, these offer less flexibility than programming-based approaches. Python and similar languages require more technical expertise, but open up significantly more design freedom and customization options for data mining.
The decision parameters for the tool selection include:
- users' expertise: Visual workflows for newcomers, programming for experts
- Project requirements: Standard analyses versus individual solutions
- Scalability: from prototyping to productive systems
- Integration: Connection to existing data sources and systems
- Budget: Open source versus commercial solutions
Ultimately, you should choose the tool that best suits your requirements and skills. A step-by-step approach often makes sense: start with visual tools for initial experiments, then switch to more flexible programming environments for productive systems.
Challenges and typical mistakes in data mining projects
Data mining projects often fail not because of a lack of technical know-how, but because of fundamental problems that arise as early as the planning phase. Awareness of these pitfalls can make the difference between success and failure.
Data quality as the biggest problem is at the top of all challenges. practitioners from the industry describe data quality as the biggest hurdle, with the problem growing exponentially with the size of the company and the volume of data. The difficulties are manifold: incomplete data, noise, contradictory information, different scales and definitions of terms. The reality of data mining shows an enormous amount of chaos in raw data, which has to be cleaned up at great expense before each analysis.
Data availability and data volume are often underestimated. Many projects start with great ambitions without checking whether sufficient high-quality data is available. The necessary data basis for ambitious use cases is often lacking, or the amount of data available is insufficient. Robust models often require thousands to hundreds of thousands of data points, significantly more than many companies initially expect.
Too little focus on data preparation regularly leads to failed projects. In practice, it has been shown time and again that significantly more time and resources are spent on cleansing and preparing the raw data than originally planned. If you underestimate this effort in data mining, you run the risk of planning with unrealistic timelines and budgets.
Other typical problems include:
- Lack of clear business objectives and unrealistic expectations
- Lack of involvement of experts experts
- Overfitting of models without adequate validation
- Neglecting the interpretability of results
- Insufficient documentation and reproducibility
The solution lies in a structured approach with close collaboration between data scientists and subject matter experts. Systematic data preparation, in which sufficient time and resources are planned for cleansing, forms the foundation for successful projects. This is the only way to avoid the most common stumbling blocks and create a solid foundation for successful data mining projects.
Best practices for successful data mining projects
Successful data mining projects follow best practices that have proven to be crucial in practice. These best practices form the foundation for reliable results and sustainable business success.
- Defining clear business objectives is the starting point for every successful project. Stakeholders and data scientists must work together to define precisely which key questions need to be answered. This ensures that the entire data mining process is aligned with overarching business objectives and that the insights gained deliver real added value.
- Ensuring data procurement and data hygiene forms the technical foundation. Data mining can only deliver results as good as the underlying data allows. It is therefore essential to identify relevant data sources and bring them together in a suitable repository. The subsequent data cleansing includes the removal of noise, duplicates or inconsistent values as well as the professional handling of missing data.
- Selecting suitable methods and models requires both technical expertise and an understanding of the business. The selection should be based on the defined problem and the characteristics of the available data. Feature engineering, i.e. the selection of meaningful input variables, can significantly improve model accuracy.
- Validating and continuously optimizing models prevents overfitting and ensures robust results. Techniques such as cross-validation or the division into training and test data are indispensable. An iterative approach with continuous refinement leads to better results in data mining than trying to implement everything in one big step.
- Backing up raw data and working reproducibly enables future analyses and quality assurance. All original data should be stored unchanged, ideally in a central data lakehouse. This ensures reproducibility and enables new questions to be asked without any loss of information.
- Not ignoring anomalies, but analyzing them in context can lead to valuable insights. In the payments industry, for example, anomalies can indicate fraudulent activity. The challenge lies in distinguishing between harmless outliers and significant signals. If internal expertise is not sufficient for evaluation, experts experts should be brought in to assess the business relevance of anomalies.
- As a de facto standard, CRISP-DM offers a proven framework for data mining projects. Similar to Scrum in software development, CRISP-DM has established itself as a structured process model in practice. experts appreciate the flexibility of the framework: while the basic principles are universally applicable, each company adapts the model to its specific requirements. The established process steps offer a proven structure without limiting the scope for necessary adjustments.
These best practices are flexible enough to be adapted to different company requirements, but at the same time provide sufficient structure for successful projects.
Future outlook: Trends in data mining
Data mining is facing an exciting development that is characterized by technological advances and changing business requirements. The trends of the coming years will fundamentally change the way we work with data.
- Merging with AI, machine learning and data science is already shaping developments today. Industry experts are observing an increasing integration of these related areas. The traditional boundaries between the disciplines are becoming blurred as each specialist area brings its own strengths to the table. This convergence makes it possible to get the best out of different approaches and develop holistic solutions.
- The increasing relevance of real-time analyses is becoming a decisive competitive factor. The times when analyses were available the next day or the next week are a thing of the past. Just-in-time evaluations are becoming increasingly important as the business world accelerates. For critical applications such as machine monitoring, instant notifications via mobile devices have already become standard.
- Predictive maintenance and streaming analytics are becoming standard. Companies can use continuous data analysis to predict maintenance requirements before failures occur. This proactive approach reduces costs and significantly improves operational efficiency.
- The importance for agile, data-driven companies is growing exponentially. Organizations that successfully integrate data mining into their business processes can react faster to market changes and make well-founded decisions. The ability to gain usable insights from data in a timely manner is becoming a critical success factor.
- Democratization through no-code solutions makes data mining accessible to broader target groups. Visual workflow tools are becoming increasingly powerful and enable even non-programmers to carry out complex analyses.
- AI-supported automation will revolutionize the entire data mining process. From automatic data cleansing and model selection to the interpretation of results, intelligent systems and large language models will support data scientists and accelerate projects.
Data mining as a competitive advantage of the future
Data mining has evolved from a niche technology to an indispensable business strategy. Companies that successfully use this technology today are creating sustainable competitive advantages in an increasingly data-driven economy.
Data mining is no longer just an option, it is a necessity for companies that want to survive in the digital economy. The tools are available, the methods are proven and the success stories speak for themselves. Now it's up to you to take advantage of these opportunities and give your company the decisive edge.
If you want to delve deeper into the world of data mining and expand your knowledge in a practical way, you will find the right entry point in our data analysis training courses, from the basics to advanced applications.