
7 Gründe, warum es sich jetzt lohnt, Python zu lernen!
Data Scientist mit Python
Data Pipelines mit Machine-Learning-Algorithmen und Python – das Online-Training mit Abschlusszertifikat

Daten automatisiert und in Echtzeit verarbeiten, analysieren und daraus Erkenntnisse ableiten zu können, gehört zu den zentralen Anforderungen von Unternehmen. Die Daten-Pipelines dafür aufzubauen, ist die Aufgabe von Data Scientists – ein Berufsfeld, das derzeit besonders gefragt ist und große Chancen bietet. Diese zertifizierte Online-Weiterbildung befähigt dich, Data-Mining-Prozesse aufzusetzen, Machine-Learning-Algorithmen anzuwenden, Prognosemodelle zu erstellen und diese in automatisierten Workflows produktiv zu setzen. Dabei wird die Programmiersprache Python mit ihren führenden Machine-Learning-Bibliotheken verwendet. Dieser Online-Kurs ist so konzipiert, dass du flexibel und in deinem eigenen Tempo innerhalb der Zugriffsdauer lernen kannst. Es erwarten dich Videos, interaktive Grafiken, Texte und viele praktische Übungen mit umfangreichen Datensätzen und Coding-Aufgaben. Bei Fragen stehen dir erfahrene Datenanalyst:innen als Mentor:innen zur Seite.

Das Online-Training ist von der Staatlichen Zentralstelle für Fernunterricht (ZFU) in Köln unter der Nummer 73597 geprüft und zugelassen.
Weiterbildung nach KI-VO Art. 4 für die Nachweispflicht von KI-Kompetenz
1. Grundlagen Data Analytics mit Python
- Arbeiten mit dem Data Lab.
- Grundlagen und Konzepte in Python.
- Vorstellung der Tools pandas, matplotlib und seaborn.
- Datenbankanfragen mit SQL Alchemy.
2. Lineare Algebra
- Mathematische Hintergründe.
- Grundbegriffe der linearen Algebra.
- Berechnung mit Vektoren und Matrizen.
- Einsatz der Python-Bibliothek numpy.
3. Wahrscheinlichkeitsverteilung
- Statistik in Data-Science-Algorithmen.
- Diskrete und kontinuierliche Verteilungen.
- Versionierung von Code in Git.
4. Überwachtes Lernen (Regression)
- Lineare Regression einsetzen.
- Einsatz des Python-Pakets sklearn.
- Regressionsmodelle verstehen.
- Evaluation der Prognosen.
- Bias-Variance-Trade-Off und Regularisierung.
- Messung der Modellgüte.
5. Überwachtes Lernen (Klassifikation)
- Konzepte des Supervised Learning.
- Einführung in Klassifikationsalgorithmen.
- Der k-Nearest-Neighbors-Algorithmus.
- Einschätzung der Klassifikationsperformance.
- Optimierung der Parameter.
- Aufteilung der Daten in Trainings- und Evaluationssets.
6. Unüberwachtes Lernen (Clustering)
- Konzepte des Unsupervised Learning.
- Der k-Means-Algorithmus.
- Evaluation der Performance-Metriken.
- Alternativen zum k-Means-Clustering.
7. Unüberwachtes Lernen (Dimensionsreduktion)
- Dimensionen in der Datenbetrachtung reduzieren.
- Principal Component Analysis (PCA).
- Unkorrelierte Features aus Ursprungsdaten erzeugen.
- Einführung in Feature Engineering.
8. Ausreißer identifizieren und ausschließen
- Methoden zur Erkennung von Ausreißern.
- Kriterien ungewöhnlicher Datenpunkte.
- Robuste Maße und Reduktion der Einflüsse durch Ausreißer.
9. Daten sammeln und zusammenführen
- Daten aus Webseiten und PDF-Dokumenten auslesen.
- Einsatz von Regulären Ausdrücken.
- Textdaten vor der Verarbeitung strukturieren.
10. Logistische Regression
- Konzepte der logistischen Regression.
- Performance-Metriken zur Evaluation.
- Nicht-numerische Daten in Modellen einsetzen.
11. Entscheidungsbäume und Random Forests
- Das Konzept der Decision Trees.
- Mehrere Modelle zu Ensembles kombinieren.
- Methoden zur Verbesserung der Vorhersagequalität.
12. Support Vector Machines
- Einsatz von Support Vector Machines (SVM).
- Einführung in Natural Language Processing (NLP).
- Textklassifikation mit Bag-of-Words-Modellen.
13. Neuronale Netze
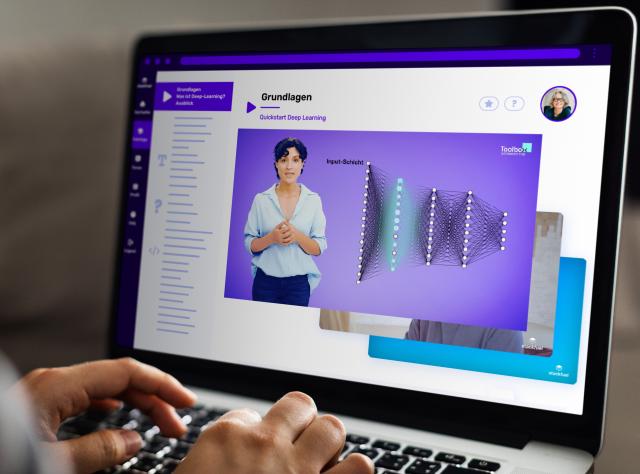
- Grundlagen Künstlicher Neuronaler Netze (KNN).
- Grundlagen des Deep Learnings.
- Tieferes Verständnis der Schichten in KNN.
14. Visualisierung und Model Interpretation
- Funktionsweisen von Modellen ableiten und darstellen.
- Methoden zur Interpretation und Visualisierung.
- Modellagnostische Methoden anwenden.
15. Verteilte Datenbanken einsetzen
- Das Python-Paket PySpark einsetzen.
- Daten aus verteilten Datenbanken auslesen.
- Grundlagen von Big-Data-Analysen.
- Machine-Learning-Algorithmen in verteilten Systemen nutzen.
16. Übungsprojekt
- Umfassendes Übungsprojekt selbstständig bearbeiten.
- Prädiktionsproblem mithilfe eines größeren Datensets lösen.
- Vorbereitung für das Abschlussprojekt.
17. Abschlussprojekt
- Selbstständige Analyse des Datenprojekts.
- Ergebnispräsentation und 1:1-Feedbackgespräch mit Mentor:innen-Team.
- Erhalt des Zertifikats zum Data Scientist mit Python.
In diesem praxisorientierten Training lernst du, selbstständig Datenanalysen mit großen Datensets durchzuführen.
Du lernst kompetent mit Python umzugehen, die Programmiersprache zur Datenauswertung einzusetzen und effektive Visualisierungen zu erstellen.
Du erfährst, wie du verschiedenste Datenquellen anbinden, Daten darin filtern und daraus zusammenführen kannst.
Du lernst umfassend Methoden, Algorithmen und Technologien des Machine Learnings kennen und erfährst, wie du diese mit Python-Paketen einsetzen kannst.
Du erfährst alles Wichtige über den Einsatz von Deep Learning und erzeugst ein künstliches neuronales Netz mit mehreren Schichten.
Nach dem Training bist du in der Lage Unternehmensdaten zu untersuchen, aussagekräftig zu visualisieren und in dynamischen Dashboards interaktiv zugänglich zu machen.
Die technischen Einstiegshürden werden durch den Einsatz von Jupyter Notebooks minimiert, mit denen du die Programmierübungen direkt im Browser durchführen kannst.
Dieser Online-Kurs bietet dir ein besonders praxisorientiertes Lernkonzept mit umfassenden Selbstlerneinheiten und einem Mentor:innen-Team, das dir durchgängig zur Verfügung steht. Jede Woche wird ein neues Kapitel für dich freigeschaltet. Mit einem Zeitbudget von circa 6 Stunden pro Woche kommst du in 17 Wochen sicher ans Ziel. So lernst du in dem Kurs:
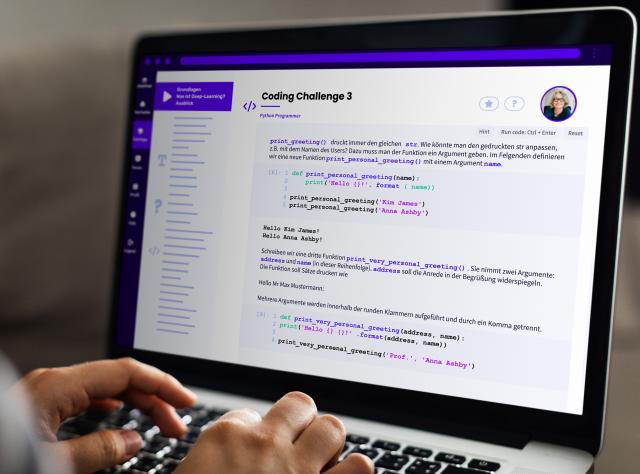
Data Lab: In der Lernumgebung des Kurses erwarten dich Videos, interaktive Grafiken, Text und vor allem viele Praxisübungen mit umfassenden Datasets und Coding-Aufgaben. Diese führst du direkt im Browser aus – ohne Installations- oder Konfigurationsaufwand und mit direkter Erfolgskontrolle.
Mentor:innen-Team: Für jegliche Fragen stehen dir deine Lern-Coaches bereit. Dabei handelt es sich um erfahrene Data Analysts, die dir gern weiterhelfen – per Chat, Audio- oder Videocall.
Webinare: Einmal wöchentlich hast du die Möglichkeit, an Webinaren teilzunehmen und darin in ausgewählte Spezialthemen der Datenanalyse einzutauchen.
Karriere-Coaching: Welche beruflichen Ziele verfolgst du mit deiner Weiterbildung und wie kannst du diese erreichen? Ein Mentor:innen-Team steht für dich bereit, um dir bei der Umsetzung deiner Karriereziele behilflich zu sein.
Abschlussprojekt: In einem eigenen Datenprojekt durchläufst du selbstständig die gesamte Daten-Pipeline und beantwortest typische Fragestellungen. Am Ende präsentierst du dein Projekt in einem 1-zu-1-Feedbackgespräch mit deinem Mentor:innen-Team.
Zertifikat: Nach dem Abschlussprojekt erhältst du dein offizielles Zertifikat zum Data Scientist mit Python.
Diese Online-Weiterbildung wird von unserem Partner StackFuel GmbH durchgeführt. StackFuel ist Spezialist im Bereich Weiterbildungen zu Data Literacy, Data Science und KI.
alle, die eine umfassende Schulung über Machine Learning und Data Pipelines suchen. Es werden Grundkenntnisse in Python vorausgesetzt. Die Weiterbildung eignet sich auch für Quereinsteiger:innen.
Digitales Lernen für Einzelpersonen
Buchungs-Nr.:
30354
30354
€ 4.500,-
zzgl. MwSt
18 Wochen (6
…
Online
11 Termine
 Auch als englischsprachiges Training buchbar:
Auch als englischsprachiges Training buchbar:
Data Scientist with Python
In Kooperation mit

Zukunft können
Daten analysieren, Muster erkennen, Vorhersagen treffen – mit der Master Class "Data Analyst".

Weitere Empfehlungen zu „Data Scientist mit Python“
Starttermine und Details
27.07.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
10.08.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
24.08.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
07.09.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
21.09.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
05.10.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
19.10.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
02.11.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
16.11.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
30.11.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
14.12.2026
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
Buchungsnummer:
30354
€ 4.500,- zzgl. MwSt.
€ 5.355,- inkl. MwSt.
Weiterbildung planen
18 Wochen (6 Std./Woche)
Das könnte dich auch interessieren:
Lade Empfehlungen
Das Training wird in Zusammenarbeit mit einem autorisierten Trainingspartner durchgeführt.
Dieser erhebt und verarbeitet Daten in eigener Verantwortung. Bitte nehme die entsprechende Datenschutzerklärung zur Kenntnis.
Über uns – Die Haufe Akademie
Seit 1978 dein Optimierer, Innovator und Begleiter–
Dein professioneller Partner für berufliche Weiterbildung und Seminare, Schulungen und aktuelle Tagungen.
Ob vor Ort, Live-Online oder Inhouse - unsere individuellen Lösungen, unser Anspruch auf höchste Beratungskompetenz und auf dich abgestimmte Weiterbildung, vereinfachen den Erwerb von Kompetenzen für die Arbeitswelt der Zukunft und erleichtern nachhaltig die berufliche Weiterentwicklung.
Ein breites Seminar-Angebot, individuelles Coaching und unsere flexiblen Formate unterstützen HR-Verantwortliche und Entscheidende bei der Zukunftsgestaltung und Personalentwicklung von Mitarbeitenden, firmeninternen Teams und Unternehmen.
Erlebe bei uns auch von zu Hause aus die Vorzüge einer Online Weiterbildung. Unsere Online-Formate entsprechen den höchsten Ansprüchen an Qualität und stehen den Präsenzveranstaltungen auch in der Praxisnähe in nichts nach. Gemeinsam Live-Online lernen in interaktiven Gruppen oder auch digital zu einem Zeitpunkt deiner Wahl.
3.600+ Weiterbildungen
690.000+ Lernende pro Jahr
Über 95% positive Bewertungen
2.600+ Trainer:innen und Coach:innen
19.000+ durchgeführte Trainings pro Jahr
Noch nicht gefunden, wonach du suchst?
Rufe uns an oder maile uns
Hast du Fragen?
Wir sind Montag bis Freitag von 8:00 bis 17:00 Uhr für dich da.

*Pflichtfelder
FAQs
Fragen & Antworten
In unserem Bereich Fragen & Antworten (FAQ) findest du alle Antworten und die häufigsten Fragen zu deinem ausgewählten Thema.
Haufe Akademie GmbH & Co. KG
Munzinger Str. 9
79111 Freiburg
Munzinger Str. 9
79111 Freiburg
Eine Marke der
Unternehmen
Über unser Angebot
- Planungssicherheit
- Freie Seminarplätze
- Qualitätsstandards
- Planung und Locations
- Fördermöglichkeiten
- Weiterbildungs-App
- Unternehmenslösungen
Besondere Angebote
Kontakt & Support
Weiterbildung finden - mit KI-Power!
Beschreibe was du suchst und erhalte passende Weiterbildungen vom KI-Berater – schnell und treffsicher.
Text in Zwischenablage gespeichert