Data Mining verstehen: Muster erkennen und Chancen nutzen


Inhalte
Data Mining: Der Schlüssel zu versteckten Mustern in deinen Daten
Jeden Tag entstehen unvorstellbare Datenmengen, von Online-Käufen über Social-Media-Posts bis hin zu Sensordaten in Maschinen. Doch nur ein Bruchteil dieser Informationen wird tatsächlich genutzt. Die große Frage lautet: Wie verwandelst du Rohdaten in wertvolle Erkenntnisse? Genau hier setzt Data Mining an: Es bringt Ordnung ins Datenchaos und macht Muster sichtbar, die dein Unternehmen voranbringen.
In diesem Beitrag erfährst du, was Data Mining genau ist, mit welchen Methoden und Techniken es arbeitet, welche praxisnahen Anwendungsfälle es gibt und welche Tools dich dabei unterstützen können. Außerdem beleuchten wir typische Herausforderungen, Best Practices für erfolgreiche Projekte und die wichtigsten Trends, die den Einsatz von Data Mining in den kommenden Jahren prägen werden.
Was ist Data Mining?
[DEFINITION][Data Mining][Data Mining ist ein systematischer Prozess zur Analyse großer Datenbestände mit dem Ziel, verborgene Muster, Trends und Zusammenhänge zu entdecken und in nützliche Informationen zu überführen. Dieser Prozess wird oft auch als Knowledge Discovery in Data (KDD) bezeichnet und bildet die Grundlage für datengetriebene Entscheidungsfindung in Unternehmen.]
Das Hauptziel von Data Mining liegt darin, aus umfangreichen Datenbeständen Muster, Zusammenhänge und Prognosen zu gewinnen, die ohne computergestützte Analyse verborgen bleiben würden. Durch den Einsatz von Algorithmen aus der künstlichen Intelligenz, dem maschinellen Lernen und der Statistik können Unternehmen Erkenntnisse gewinnen, die ihre Geschäftsstrategien maßgeblich beeinflussen.
Zur besseren Einordnung ist es wichtig, Data Mining von verwandten Disziplinen abzugrenzen:
- Business Intelligence konzentriert sich darauf, historische Daten aufzubereiten und in Dashboards zu visualisieren. Es beantwortet die Frage „Was ist passiert?".
- Machine Learning hingegen nutzt Algorithmen, um aus Daten zu lernen und Vorhersagen zu treffen.
- Data Science umfasst als übergeordnete Disziplin alle diese Bereiche und mehr.
Data Mining positioniert sich als der Prozess, der zwischen der reinen Datensammlung und der praktischen Anwendung steht. Es macht die versteckten Zusammenhänge in deinen Daten sichtbar und nutzbar.
Methoden und Techniken im Data Mining
Data Mining umfasst verschiedene Kernaufgaben, die je nach Fragestellung und verfügbaren Daten zum Einsatz kommen. Jede Methode hat ihre spezifischen Stärken und eignet sich für unterschiedliche Anwendungsszenarien. Häufig verwendete Methoden sind die folgenden:
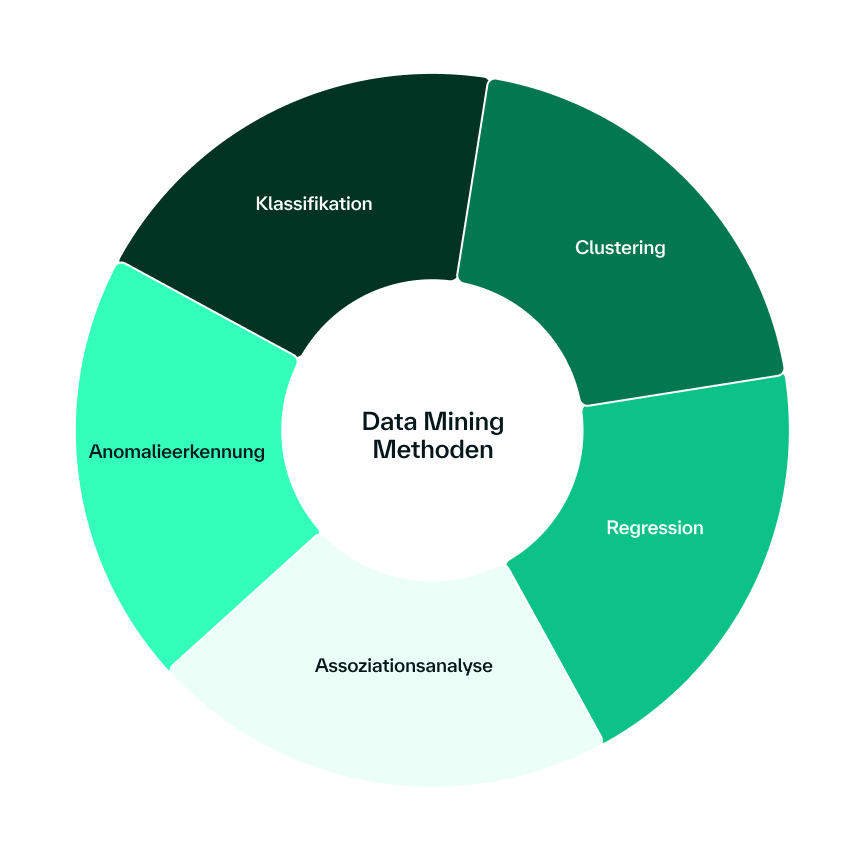
- Klassifikation ist eine überwachte Lernmethode, bei der Datenpunkte vordefinierten Kategorien oder Klassen zugeordnet werden. Ein Modell wird auf gelabelten Datensätzen trainiert, um Muster zu erkennen und neue Daten korrekt einzuordnen. Typische Anwendungen findest du in der Spam-Erkennung, wo E-Mails automatisch als "Spam" oder "Kein Spam" klassifiziert werden, oder bei Kreditwürdigkeitsprüfungen, wo Kunden in Risikogruppen eingeteilt werden.
- Clustering arbeitet unüberwacht und gruppiert Datenpunkte nach Ähnlichkeit, ohne dass vordefinierte Klassen existieren. Diese Methode hilft dabei, unbekannte Muster und Gruppierungen in den Daten zu entdecken. Ein praktisches Beispiel ist die Kundensegmentierung, bei der du deine Kunden basierend auf ihrem Kaufverhalten in verschiedene Gruppen unterteilst. Auch die Anomalieerkennung nutzt Clustering-Verfahren, um ungewöhnliche Datenpunkte zu identifizieren.
- Regression ermöglicht die Vorhersage kontinuierlicher Zahlenwerte auf Basis bestehender Daten und erkannter Zusammenhänge zwischen Variablen. Diese Technik des Data Minings kommt bei Preis- oder Absatzprognosen zum Einsatz, wo du beispielsweise zukünftige Verkaufszahlen basierend auf historischen Daten und externen Faktoren vorhersagst.
- Assoziationsanalyse identifiziert interessante Beziehungen und Muster zwischen verschiedenen Variablen in großen Datenbeständen. Das bekannteste Beispiel ist die Warenkorbanalyse im Einzelhandel, wo erkannt wird, welche Produkte häufig zusammen gekauft werden. Diese Erkenntnisse ermöglichen gezielte Cross-Selling-Strategien und optimierte Produktplatzierungen.
- Anomalieerkennung spürt auffällige Ausreißer oder ungewöhnliche Muster auf, die von der Norm abweichen. Diese Technik ist besonders wertvoll für die Betrugserkennung. Ungewöhnliche Transaktionsmuster können auf betrügerische Aktivitäten hinweisen, während anomale Netzwerkverkehrsmuster Cyberangriffe signalisieren können.
Die Auswahl der richtigen Methode hängt von mehreren Faktoren ab. Expert:innen betonen, dass die Art der verfügbaren Daten den Ansatz bestimmt: Bei gelabelten Daten mit bekannten Beispielergebnissen eignen sich überwachte Lernverfahren wie Klassifikation oder Regression. Ohne Labels kommen unüberwachte Methoden wie Clustering zum Einsatz. Zusätzlich entscheidet der gewünschte Output-Typ: Kontinuierliche Werte erfordern Regression, während diskrete Kategorien Klassifikationsverfahren benötigen. Die Datenqualität, verfügbare Labels und die konkrete Fragestellung bestimmen letztendlich, welcher Ansatz zum Erfolg führt.
Praxisnahe Anwendungsfälle von Data Mining
Data Mining entfaltet seinen wahren Wert in der praktischen Anwendung, wo es konkrete Geschäftsprobleme löst und messbaren Mehrwert schafft. Die Bandbreite der Einsatzgebiete ist beeindruckend und wächst kontinuierlich.
Betrugserkennung und Sicherheit gehören zu den wichtigsten Anwendungsfeldern. Zahlungsanbieter wie Visa, Mastercard oder PayPal nutzen Data Mining, um betrügerische Transaktionen in Echtzeit zu erkennen. Diese Unternehmen haben umfangreiche Daten zu normalen Zahlungsvorgängen gesammelt. Weicht ein Zahlungsvorgang stark von diesen etablierten Mustern ab, wird eine Anomalie erkannt und der Vorgang zur weiteren Prüfung markiert. Ähnliche Ansätze kommen in der Cybersecurity zum Einsatz, wo ungewöhnliche Netzwerkaktivitäten auf potenzielle Angriffe hinweisen.
Marketing und Kundenbindung profitieren erheblich von Data Mining-Techniken. Durch die Segmentierung deiner Kunden in verschiedene Gruppen lassen sich passgenaue Marketingstrategien entwickeln. So kann das Budget gezielt verteilt werden: Kunden mit hoher Kaufwahrscheinlichkeit erhalten beispielsweise einen größeren Anteil der Ressourcen, während andere Gruppen mit angepassten Maßnahmen adressiert werden. Dieses Vorgehen steigert die Effizienz der Kampagnen und maximiert den Return on Investment.
Clustering-Algorithmen bieten praktische Lösungen für komplexe Kundensegmentierungen, die mit herkömmlichen Tools wie Excel nicht bewältigbar wären. Durch die systematische Analyse großer Kundendatenbanken lassen sich unterschiedliche Kundentypen identifizieren, für die jeweils spezifische Marketing- und Betreuungsansätze entwickelt werden können. Diese Segmentierung ermöglicht eine deutlich effizientere Ressourcenallokation und zielgerichtete Kundenansprache.
In der Bildung findet Data Mining Anwendung, um Lernergebnisse zu verbessern und personalisierten Unterricht zu ermöglichen. Bildungseinrichtungen können anhand von Leistungsdaten gefährdete Schüler identifizieren und frühzeitig unterstützen. Darüber hinaus ermöglichen Data Mining-gestützte Empfehlungssysteme personalisierte Kursempfehlungen, die auf individuellen Lernmustern und -präferenzen basieren.
Tools und Werkzeuge im Data Mining
Die Auswahl der richtigen Tools kann über Erfolg oder Misserfolg deines Data Mining-Projekts entscheiden. Je nach Anforderungen, Teamkompetenzen und Projektzielen stehen verschiedene Lösungen zur Verfügung.
Open-Source-Lösungen bieten einen kostengünstigen Einstieg in die Welt des Data Mining:
- Weka ist besonders in Forschung und Lehre beliebt und bietet eine benutzerfreundliche Oberfläche mit einer Vielzahl von Machine Learning-Algorithmen.
- Rapid Miner ermöglicht es, komplette Data Mining-Workflows visuell zu erstellen und zu automatisieren, von der Datenvorverarbeitung bis zum Modelltraining.
- Orange punktet mit seinem fokussierten visuellen Interface und erlaubt die einfache Zusammenstellung von Pipelines per Drag-and-Drop.
- KNIME basiert auf einem modularen Knotensystem und wird oft in professionellen Umgebungen für Workflow-gestützte Analysen eingesetzt.
Programmiersprachen und Frameworks bieten maximale Flexibilität für komplexe Anforderungen. Python hat sich als Standardsprache für das Data Mining etabliert, unterstützt von mächtigen Bibliotheken wie scikit-learn für Machine Learning, Pandas für Datenmanipulation, NumPy für numerische Berechnungen sowie Matplotlib und Seaborn für Visualisierungen. Für neuronale Netzwerke kommen TensorFlow und PyTorch zum Einsatz.
Die Wahl zwischen visuellen Tools und programmiersprachenbasierten Lösungen hängt von deinem Team ab. Praktiker:innen empfehlen, die Auswahl an den vorhandenen Kompetenzen auszurichten: Teams ohne Programmiererfahrung profitieren von visuellen Workflow-Tools mit vorgefertigten Modulen, die schnell zusammengestellt werden können. Diese bieten jedoch weniger Flexibilität als programmierbasierte Ansätze. Python und ähnliche Sprachen erfordern mehr technisches Know-how, eröffnen für das Data Mining aber deutlich mehr Gestaltungsfreiräume und Anpassungsmöglichkeiten.
Die Entscheidungsparameter für die Tool-Auswahl umfassen:
- Kompetenz der Nutzer:innen: Visuelle Workflows für Einsteiger:innen, Programmierung für Expert:innen
- Projektanforderungen: Standardanalysen versus individuelle Lösungen
- Skalierbarkeit: Von Prototyping bis zu produktiven Systemen
- Integration: Anbindung an bestehende Datenquellen und Systeme
- Budget: Open-Source versus kommerzielle Lösungen
Letztendlich solltest du das Tool wählen, das am besten zu deinen Anforderungen und Kompetenzen passt. Oft ist ein schrittweiser Ansatz sinnvoll: Start mit visuellen Tools für erste Experimente, dann Wechsel zu flexibleren Programmierumgebungen für produktive Systeme.
Herausforderungen und typische Fehler in Data Mining-Projekten
Data Mining-Projekte scheitern häufig nicht an mangelndem technischem Know-how, sondern an grundlegenden Problemen, die bereits in der Planungsphase entstehen. Das Bewusstsein für diese Fallstricke kann den Unterschied zwischen Erfolg und Misserfolg ausmachen.
Datenqualität als größtes Problem steht an der Spitze aller Herausforderungen. Praktiker:innen aus der Branche beschreiben Datenqualität als die größte Hürde, wobei das Problem mit der Unternehmensgröße und dem Datenvolumen exponentiell wächst. Die Schwierigkeiten sind vielfältig: unvollständige Daten, Rauschen, widersprüchliche Informationen, verschiedene Skalen und Begriffsdefinitionen. Die Realität des Data Minings zeigt ein enormes Maß an Chaos in Rohdaten, das vor jeder Analyse aufwendig bereinigt werden muss.
Datenverfügbarkeit und Datenmenge werden oft unterschätzt. Viele Projekte starten mit großen Ambitionen, ohne zu prüfen, ob ausreichend qualitativ hochwertige Daten vorhanden sind. Häufig fehlen die notwendigen Datengrundlagen für ambitionierte Anwendungsfälle, oder die verfügbare Datenmenge ist unzureichend. Für robuste Modelle werden oft Tausende bis Hunderttausende von Datenpunkten benötigt, deutlich mehr, als viele Unternehmen initial erwarten.
Zu wenig Fokus auf Datenaufbereitung führt regelmäßig zu gescheiterten Projekten. In der Praxis zeigt sich immer wieder, dass deutlich mehr Zeit und Ressourcen in die Bereinigung und Aufbereitung der Rohdaten fließen, als ursprünglich eingeplant wird. Wer diesen Aufwand beim Data Mining unterschätzt, läuft Gefahr, mit unrealistischen Timelines und Budgets zu planen.
Weitere typische Probleme umfassen:
- Fehlende klare Geschäftsziele und unrealistische Erwartungen
- Mangelnde Einbindung von Domain-Expert:innen
- Überanpassung von Modellen ohne adäquate Validierung
- Vernachlässigung der Interpretierbarkeit von Ergebnissen
- Unzureichende Dokumentation und Reproduzierbarkeit
Die Lösung liegt in einer strukturierten Herangehensweise mit enger Zusammenarbeit zwischen Datenwissenschaftler:innen und Fachexpert:innen. Eine systematische Datenvorbereitung, bei der ausreichend Zeit und Ressourcen für die Bereinigung eingeplant werden, bildet das Fundament für erfolgreiche Projekte. Nur so lassen sich die häufigsten Stolpersteine vermeiden und solide Grundlagen für erfolgreiche Data Mining-Projekte schaffen.
Best Practices für erfolgreiche Data Mining-Projekte
Erfolgreiche Data Mining-Projekte folgen bewährten Praktiken, die sich in der Praxis als entscheidend erwiesen haben. Diese Best Practices bilden das Fundament für zuverlässige Ergebnisse und nachhaltigen Geschäftserfolg.
- Klare Business-Ziele definieren steht am Anfang jedes erfolgreichen Projekts. Stakeholder und Datenwissenschaftler:innen müssen gemeinsam präzise festlegen, welche Kernfragen beantwortet werden sollen. Das stellt sicher, dass der gesamte Data Mining-Prozess auf übergeordnete Geschäftsziele ausgerichtet ist und die gewonnenen Erkenntnisse echten Mehrwert liefern.
- Datenbeschaffung und Datenhygiene sicherstellen bildet das technische Fundament. Data Mining kann nur so gute Resultate liefern, wie es die zugrundeliegenden Daten erlauben. Daher ist es unabdingbar, relevante Datenquellen zu identifizieren und in einem geeigneten Repository zusammenzuführen. Die anschließende Datenbereinigung umfasst das Entfernen von Rauschen, Dubletten oder inkonsistenten Werten sowie den professionellen Umgang mit fehlenden Daten.
- Passende Methoden und Modelle wählen erfordert sowohl technische Expertise als auch Geschäftsverständnis. Die Auswahl sollte auf der definierten Problemstellung und den Eigenschaften der verfügbaren Daten basieren. Feature Engineering, also die Auswahl aussagekräftiger Eingabevariablen, kann die Modellgenauigkeit erheblich verbessern.
- Modelle validieren und kontinuierlich optimieren verhindert eine Überanpassung und gewährleistet robuste Ergebnisse. Techniken wie Cross-Validation oder die Aufteilung in Trainings- und Testdaten sind unverzichtbar. Ein iterativer Ansatz mit kontinuierlicher Verfeinerung führt zu besseren Resultaten beim Data Mining als der Versuch, alles in einem großen Schritt umzusetzen.
- Rohdaten sichern und reproduzierbar arbeiten ermöglicht zukünftige Analysen und Qualitätssicherung. Alle Originaldaten sollten unverändert gespeichert werden, idealerweise in einem zentralen Data Lakehouse. Dies gewährleistet Reproduzierbarkeit und ermöglicht neue Fragestellungen ohne Informationsverluste.
- Anomalien nicht ignorieren, sondern im Kontext analysieren kann zu wertvollen Erkenntnissen führen. In der Zahlungsbranche beispielsweise können Anomalien auf betrügerische Aktivitäten hinweisen. Die Herausforderung liegt darin, zwischen harmlosen Ausreißern undbedeutsamen Signalen zu unterscheiden. Wenn die interne Expertise zur Bewertung nicht ausreicht, sollten Domain-Expert:innen hinzugezogen werden, um die geschäftliche Relevanz von Anomalien zu bewerten.
- CRISP-DM als De-facto-Standard bietet einen bewährten Rahmen für Data Mining-Projekte. Ähnlich wie Scrum in der Softwareentwicklung hat sich CRISP-DM als strukturiertes Vorgehensmodell in der Praxis durchgesetzt. Expert:innen schätzen die Flexibilität des Frameworks: Während die Grundprinzipien universell anwendbar sind, passt jedes Unternehmen das Modell an seine spezifischen Anforderungen an. Die etablierten Prozessschritte bieten eine bewährte Struktur, ohne dabei Raum für notwendige Anpassungen zu beschränken.
Diese Best Practices sind flexibel genug, um an verschiedene Unternehmensanforderungen angepasst zu werden, bieten aber gleichzeitig ausreichend Struktur für erfolgreiche Projekte.
Zukunftsausblick: Trends im Data Mining
Data Mining steht vor einer spannenden Entwicklung, die von technologischen Fortschritten und veränderten Geschäftsanforderungen geprägt wird. Die Trends der kommenden Jahre werden die Art, wie wir mit Daten arbeiten, grundlegend verändern.
- Verschmelzung mit KI, Machine Learning und Data Science prägt bereits heute die Entwicklung. Branchenkenner:innen beobachten eine zunehmende Integration dieser verwandten Bereiche. Die traditionellen Grenzen zwischen den Disziplinen verschwimmen, da jeder Fachbereich eigene Stärken mitbringt. Diese Konvergenz ermöglicht es, aus verschiedenen Ansätzen das Beste herauszuholen und ganzheitliche Lösungen zu entwickeln.
- Zunehmende Relevanz von Echtzeit-Analysen wird zu einem entscheidenden Wettbewerbsfaktor. Die Zeiten, in denen Analysen am nächsten Tag oder in der nächsten Woche zur Verfügung standen, gehören der Vergangenheit an. Just-in-Time-Auswertungen werden immer wichtiger, da sich die Geschäftswelt beschleunigt. Bei kritischen Anwendungen wie der Maschinenüberwachung sind sofortige Benachrichtigungen über mobile Geräte bereits Standard geworden.
- Predictive Maintenance und Streaming Analytics werden Standard. Unternehmen können durch kontinuierliche Datenauswertung Wartungsbedarfe vorhersagen, bevor Ausfälle auftreten. Diese proaktive Herangehensweise reduziert Kosten und verbessert die Betriebseffizienz erheblich.
- Die Bedeutung für agile, datengetriebene Unternehmen wächst exponentiell. Organisationen, die Data Mining erfolgreich in ihre Geschäftsprozesse integrieren, können schneller auf Marktveränderungen reagieren und fundierte Entscheidungen treffen. Die Fähigkeit, aus Daten zeitnah verwertbare Erkenntnisse zu gewinnen, wird zum kritischen Erfolgsfaktor.
- Demokratisierung durch No-Code-Lösungen macht Data Mining für breitere Zielgruppen zugänglich. Visuelle Workflow-Tools werden immer mächtiger und ermöglichen es auch Nicht-Programmierer:innen, komplexe Analysen durchzuführen.
- KI-unterstützte Automatisierung wird den gesamten Data Mining-Prozess revolutionieren. Von der automatischen Datenbereinigung über die Modellauswahl bis zur Ergebnisinterpretation werden intelligente Systeme und Large Language Models Datenwissenschaftler:innen unterstützen und Projekte beschleunigen.
Data Mining als Wettbewerbsvorteil der Zukunft
Data Mining hat sich von einer Nischentechnologie zu einer unverzichtbaren Geschäftsstrategie entwickelt. Unternehmen, die diese Technologie heute erfolgreich einsetzen, verschaffen sich nachhaltige Wettbewerbsvorteile in einer zunehmend datengetriebenen Wirtschaft.
Data Mining ist nicht mehr nur eine Option, es ist eine Notwendigkeit für Unternehmen, die in der digitalen Wirtschaft bestehen wollen. Die Tools sind verfügbar, die Methoden bewährt, und die Erfolgsgeschichten sprechen für sich. Jetzt liegt es an dir, diese Möglichkeiten zu nutzen und deinem Unternehmen den entscheidenden Vorsprung zu verschaffen.
Wenn du tiefer in die Welt des Data Mining einsteigen und dein Wissen praxisnah erweitern möchtest, findest du in unseren Weiterbildungen rund um die Datenanalyse den passenden Einstieg, von den Grundlagen bis zu fortgeschrittenen Anwendungen.